Challenge
Often sports clubs have limited information about the number of visitors who will go to the stadium on a specific game day upfront. This is a big issue as it influences many different strategic and operational decisions. If the clubs are able to understand upfront how many visitors will come to a specific game day, they can adjust workforce, security, and resource planning decisions to the expected demand. Furthermore, different marketing actions like special promotions or advertising campaigns can be initiated early to ensure full stadiums. A data-driven forecast provides the relevant information and thereby enables these opportunities.
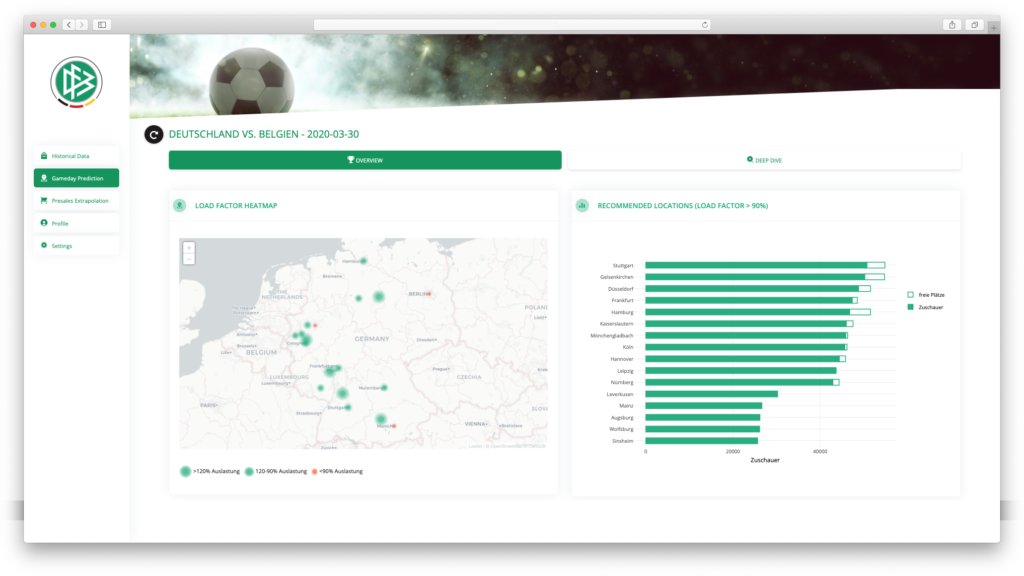
Solution
We realized this use case for the German Football Association (DFB) for which it provided an additional value. We forecasted the expected spectators for a match of the German national team for different potential stadiums. The results could be used by the DFB to select the best suited stadium, at the optimal trade-off between expected visitors and stadium capacity.
Approach
Forecasting is one of the most prominent fields of application in AI and machine learning. Various companies have already successfully applied machine learning forecasting solutions in different contexts. Typically, it is possible to generate a valid forecast based on related historical data. The general idea is to learn patterns from the historical data which are then extrapolated into the future.
For this use case, we used historical data from past matches of the German national team. This data included information about the different game days like the weekday on which the game took place, the month, the opponent and their corresponding FIFA rank, the venue, the kick-off time and most important the number of spectators. A machine learning project usually starts with an initial exploration and visualization of the data. It is important to understand the data and to gather interesting insights that can be leveraged for the forecast. The second step typically involves cleaning and transforming the data, enriching it with external information and selecting the most relevant data points which can be used for building the forecast. Then, different machine learning algorithms are benchmarked which are able to learn the hidden patterns in the data. Then, the best performing one is chosen. In this project, we’ve used a so called „random forest„, a very flexible machine learning algorithm, to solve this problem. We were able to achieve accurate estimates for the number spectators which were very close to observed number of spectators (average accuracy 91%). As a result, the DFB was able to use this information for different game day planning decisions as discussed above.